お知らせ
2018年5月15日
【Python】自社HPのページタイトルたちを形態素解析してTF-IDF値を算出する。
こんにちは。
本日はタイトルの通り、自社のHPのページタイトル達を取得して形態素解析を行いさらにTF-IDF値を取得してみようと思います。
形態素解析とは文章を”意味のある最小単位の単語に分割”する解析手法のことです。
またTF-IDFとは”単語の出現頻度(TF)“と”逆文書頻度(IDF)“の指標から文章中に含まれる単語の重要度を評価する手法のことです。
少ない文書の中で多用されている単語ほど総数の中から特徴的な単語となります。
逆に数多くの文書で横断的に多用されるワードは重要ではないという考え方です。
要は自社HP内で使用されているワードを抽出して、プログラムに各ワードの重要度を評価させましょうということです。
興味のある方はぜひGoogle先生に「TF-IDFとは」, 「ホームページ TF-IDF」とかで訪ねてみてください。
また活用方法は多岐に亘ると思いますので、
今回は試してみた程度のクオリティの記事になりますのでその感覚で読んでいただければと思います。
それでは早速やっていきましょう。
<手順1>
まずはHPのページタイトルを何かしらの手法で取得します。
弊社HPはCMSで作成されているようなので、
そちらのAPIをと思いましたが残念ながら私には権限がありませんでした。
なぜタイトルだけなのかと思った方もいると思います。そういうことです。
ということで調べてみたところこのツールが良さそうでした。
https://www.screamingfrog.co.uk/seo-spider/
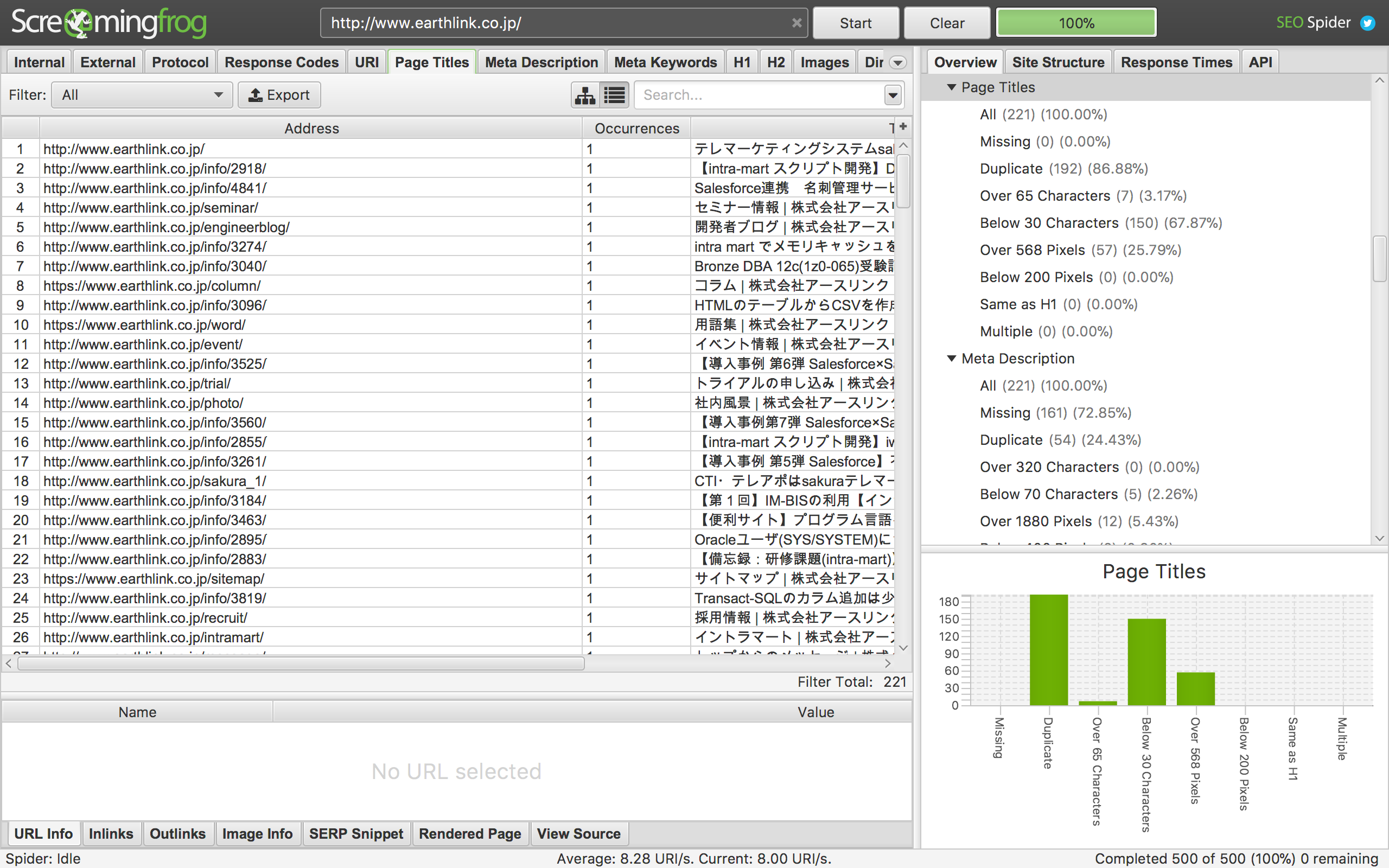
早速ダウンロードしてURLを打ち込んでいきましょう。
「Start」をクリックして完了したら「Page Title」タブを選択して「Export」するだけです。
早いですね。CSV形式で出力されますがタイトル列以外はいらないので全部削除して拡張子「.txt」に変更してください。
それからこの後にプログラムで解析するのですが、
余計な記号とかあったら解析の邪魔になる可能性があります(例えば文章中に”,”があったらとか、あと改行コードとかも)。
余裕があればエディタとかで取り除いていきましょう。
<手順2>
形態素解析を行うための前準備をします。
形態素って言葉だけでもう難しさが漂っていますが心配はありません。
そう、Mecabがあればね。
ということでインストールしていきます。
実行環境は以前EC2の記事で書いた通りです。これがやりたくて作成しました。
またMecabはPython3系が相性いいとのことですが、Ubuntu 16.04 LTSにはデフォルトでPython3系が入っております。
因みに2系も入っているのでバージョン間違えて実行しないように気をつけてください。
MecabはMecabそのものと参照対象の単語辞書によって解析を行います。
形式さえ合えば任意で作成もできるのですが今回はやっていません。
CSV作成すれば良いだけで簡単みたいです。
ということで、Mecab本体と辞書とPython上でMecabを動かすためのパッケージをインストールします。
pipコマンド使用していますので、pip3を予め使用できるようにしておいてください。
$ sudo apt-get install mecab libmecab-dev mecab-ipadic $ sudo apt-get install mecab-ipadic-utf8 $ sudo pip3 install mecab-python3
完了したらMecabをコマンド上で起動してみてください。
こんにちは今日もいい天気ですね。さようなら。 こんにちは 感動詞,*,*,*,*,*,こんにちは,コンニチハ,コンニチワ 今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー も 助詞,係助詞,*,*,*,*,も,モ,モ いい 形容詞,自立,*,*,形容詞・イイ,基本形,いい,イイ,イイ 天気 名詞,一般,*,*,*,*,天気,テンキ,テンキ です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス ね 助詞,終助詞,*,*,*,*,ね,ネ,ネ 。 記号,句点,*,*,*,*,。,。,。 さようなら 感動詞,*,*,*,*,*,さようなら,サヨウナラ,サヨーナラ 。 記号,句点,*,*,*,*,。,。,。 EOS
こんな感じになるはずです。
ついでにPythonファイル上でimportしてみて問題ないか確認しましょう。
<手順3>
ここまでいけば準備が整っているのであとはTF-IDFを計算するだけです。
ここはツールに頼りません。自力でPythonコード上で記述していくだけです。
処理の流れとしては、
(1)ファイルを取り出す
data = open('result.txt', 'r').read() text = data.split(',')
(2)Mecabを初期化して実行
tagger = MeCab.Tagger() tagger.parse('') node = tagger.parseToNode(text)
(3)TF(単語の出現頻度)値の計算
TF = 文書dに登場する単語tの出現回数 * 文書dの総単語数
(4)IDF(逆文書頻度)値の計算
IDF = math.log(単語tが出現する文書の数 * 総文書数)
(5)TF-IDF値の計算
TF-IDF = TF(単語の出現頻度) * IDF(逆文書頻度)
(6)出力
単語, TF-IDF値, TF値, IDF値, 文書d内での単語tの出現回数, 単語tの出現文書数
こんな感じで処理を行うと、
以下のように出力が行われます。(zipダウンロードリンク)
TF-IDFの値が大きい単語ほど重要度が高いということです。
同率1位が50単語ありますね。
・リードナーチャリング
・SFA
・CRM
などが上位にくるあたり弊社の特徴をよく表しているのではないでしょうか。
それにしてもMecabの精度がなんとも微妙でしたね。。
ひとまず自社名や自社製品は辞書に追加したほうがよかったです。
あと、これらの単語をPythonでWordColudに食わせてみるのもやりたいですね。。。
Mecab使うまでに時間を使いすぎてしまったようです。
ちょっと時間があるときに辞書を見直して再実行してみたいと思います。
ちなみにPythonはじめて使ってみたんですが、簡単で覚えやすくていい感じでした。
ライブラリほとんど使ってないですけど機械学習のPythonと言われるだけあって数学系の物が豊富みたいです。
機会があれば色々試してみたいですね!
Contact
お問い合わせ
0120 - 889 - 236
受付時間:平日 9:00-18:00